Summary
To secure AI systems effectively, cybersecurity professionals, AI practitioners, and penetration testers must understand how data itself can become an attack vector. Because these systems are fundamentally data-driven, their security, reliability, and integrity hinge on the quality and trustworthiness of both the data they ingest and the model artifacts they generate.
This module provides an in-depth exploration of some of the data-centric security vulnerabilities in AI systems:
- The
AI Data Pipelineand its inherent vulnerabilities Data poisoningattacks, such asLabel FlippingandTargeted Label AttacksFeature Attacks, focusing onClean Label AttacksTrojan Attacks(backdoors) in AI modelsTensor Steganographyand exploitingmodel artifactvulnerabilities
This module is broken into sections with accompanying hands-on exercises to practice each of the tactics and techniques we cover. The module ends with a practical hands-on skills assessment to gauge your understanding of the various topic areas.
You can start and stop the module at any time and pick up where you left off. There is no time limit or "grading", but you must complete all of the exercises and the skills assessment to receive the maximum number of cubes and have this module marked as complete in any paths you have chosen.
To ensure a smooth learning experience in this module, certain skills are considered mandatory: A good understanding of Python programming and familiarity with how Jupyter Notebooks operate.
A firm grasp of the following modules can be considered a prerequisite for the successful completion of this module:
- Fundamentals of AI
- Applications of AI in InfoSec
- Introduction to Red Teaming AI
- Prompt Injection Attacks
In addition, it is HIGHLY recommended you use your own PC/Laptop for the practicals in this module.
Introduction to AI Data
Artificial Intelligence (AI) systems are fundamentally data-driven. Consequently, their performance, reliability, and security are inextricably linked to the quality, integrity, and confidentiality of the data they consume and produce.
The Data Pipeline: Fueling AI Systems
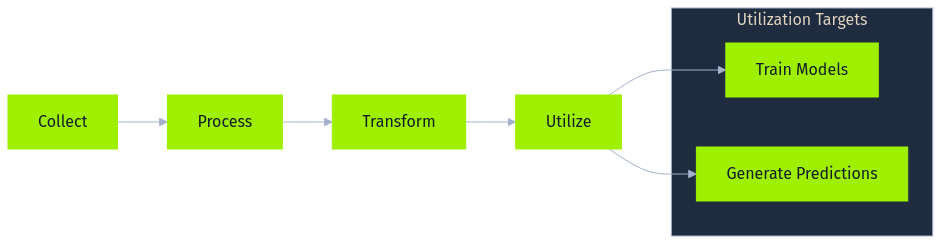
At the heart of most AI implementations lies a data pipeline, a sequence of steps designed to collect, process, transform, and ultimately utilize data for tasks such as training models or generating predictions. While the specifics vary greatly depending on the application and organization, a general data pipeline often includes several core stages, frequently leveraging specific technologies and handling diverse data formats.
Data Collection
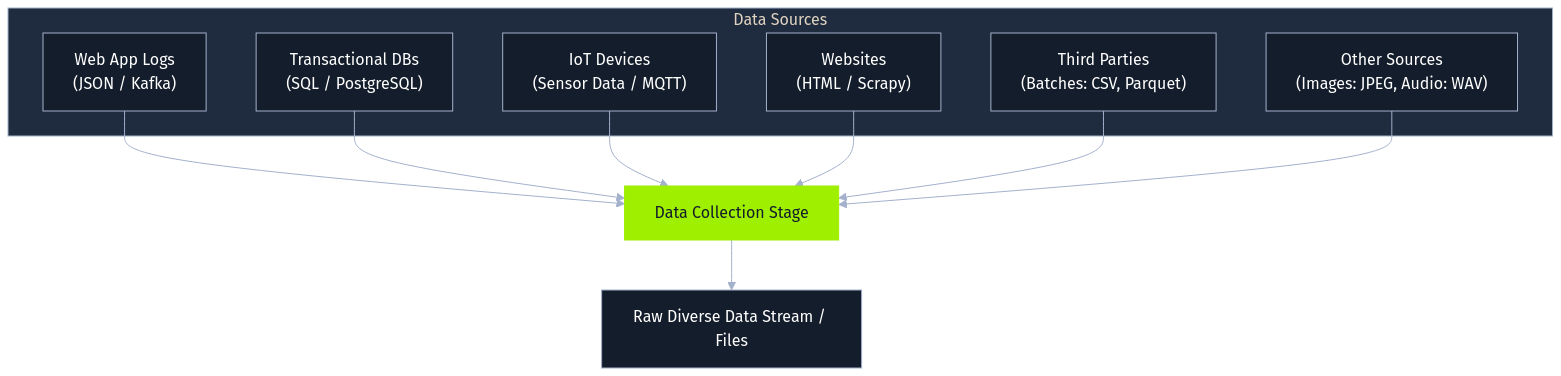
The process begins with data collection, gathering raw information from various sources. This might involve capturing user interactions from web applications as JSON logs streamed via messaging queues like Apache Kafka, ingesting structured transaction records from SQL databases like PostgreSQL, pulling sensor readings via MQTT from IoT devices, scraping public websites using tools like Scrapy, or receiving batch files (CSV, Parquet) from third parties. The collected data can range from images (JPEG) and audio (WAV) to complex semi-structured formats. The initial quality and integrity of this collected data profoundly impact all downstream processes.
Storage

Following collection, data requires storage. The choice of technology hinges on the data's structure, volume, and access patterns. Structured data often resides in relational databases (PostgreSQL), while semi-structured logs might use NoSQL databases (MongoDB). For large, diverse datasets, organizations frequently employ data lakes built on distributed file systems (Hadoop HDFS) or cloud object storage (AWS S3, Azure Blob Storage). Specialized databases like InfluxDB cater to time-series data. Importantly, trained models themselves become stored artifacts, often serialized into formats like Python's pickle (.pkl), ONNX, or framework-specific files (.pt, .pth, .safetensors), each presenting unique security considerations if handled improperly.
Data Processing
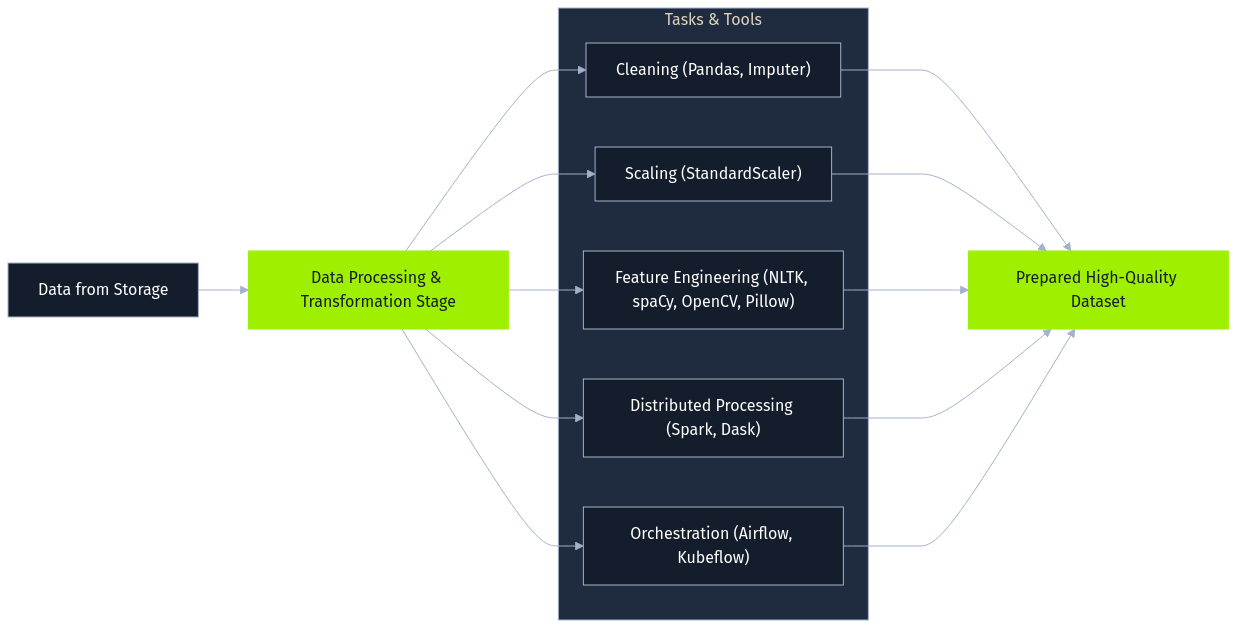
Next, raw data undergoes data processing and transformation, as it's rarely suitable for direct model use. This stage employs various libraries and frameworks for cleaning, normalization, and feature engineering. Data cleaning might involve handling missing values using Pandas and scikit-learn's Imputers. Feature scaling often uses StandardScaler or MinMaxScaler. Feature engineering creates new relevant inputs, such as extracting date components or, for text data, performing tokenization and embedding generation using NLTK or spaCy. Image data might be augmented using OpenCV or Pillow. Large datasets often necessitate distributed processing frameworks like Apache Spark or Dask, with orchestration tools like Apache Airflow or Kubeflow Pipelines managing these complex workflows. The objective is to prepare a high-quality dataset optimized for the AI task.
Modeling

The processed data then fuels the analysis and modeling stage. Data scientists and ML engineers explore the data, often within interactive environments like Jupyter Notebooks, and train models using frameworks such as scikit-learn, TensorFlow, Jax, or PyTorch. This iterative process involves selecting algorithms (e.g., RandomForestClassifier, CNNs), tuning hyperparameters (perhaps using Optuna), and validating performance. Cloud platforms like AWS SageMaker or Azure Machine Learning often provide integrated environments for this lifecycle.
Deployment
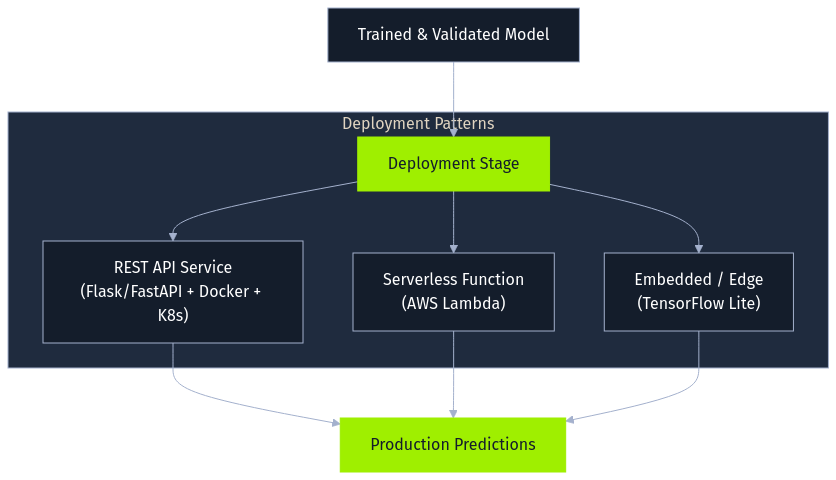
Once trained and validated, a model enters the deployment stage, where it's integrated into a production environment to serve predictions. Common patterns include exposing the model as a REST API using frameworks like Flask or FastAPI, often containerized with Docker and orchestrated by Kubernetes. Alternatively, models might become serverless functions (AWS Lambda) or be embedded directly into applications or edge devices (using formats like TensorFlow Lite). Securing the deployed model file and its surrounding infrastructure is a key concern here.
Monitoring and Maintenance
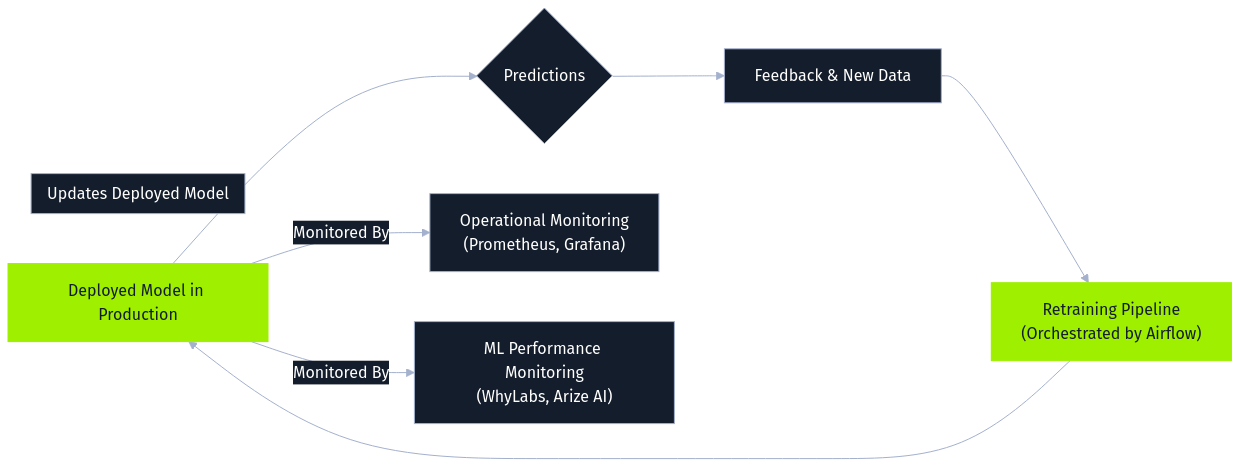
Finally, monitoring and maintenance constitute an ongoing stage. Deployed models are continuously observed for operational health using tools like Prometheus and Grafana, while specialized ML monitoring platforms (WhyLabs, Arize AI) track data drift, concept drift, and prediction quality. Feedback from predictions and user interactions is logged and often processed alongside newly collected data to periodically retrain the model. This retraining is essential for adapting to changing patterns and maintaining performance but simultaneously creates a significant attack vector. Malicious data introduced via feedback loops or ongoing collection can be incorporated during retraining, enabling online poisoning attacks. Orchestration tools like Airflow often manage these retraining pipelines, making the security of data flowing into them critical.
Two Pipeline Examples
To clearly illustrate these complex pipelines, lets consider two examples:
First, an e-commerce platform building a product recommendation system collects user activity (JSON logs via Kafka) and reviews (text). This raw data lands in a data lake (AWS S3). Apache Spark processes this data, reconstructing sessions and performing sentiment analysis (NLTK) on reviews, outputting Parquet files. Within AWS SageMaker, a recommendation model is trained on this processed data. The resulting model file (pickle format) is stored back in S3 before being deployed via a Docker-ized Flask API on Kubernetes. Monitoring tracks click-through rates, and user feedback along with new interaction data feeds into periodic retraining cycles managed by Airflow, aiming to keep recommendations relevant but also opening the door for potential poisoning through manipulated feedback.
Second, a healthcare provider developing a predictive diagnostic tool collects anonymized patient images (DICOM) and notes (XML) from PACS and EHR systems. Secure storage (e.g., HIPAA-compliant AWS S3) is a requirement here. Python scripts using Pydicom, OpenCV, and spaCy process the data, standardizing images and extracting features. PyTorch trains a deep learning model (CNN) on specialized hardware. The validated model (.pt file) is securely stored and then deployed via an internal API to a clinical decision support system. Monitoring tracks diagnostic accuracy and data drift. While retraining might be less frequent and more rigorously controlled here, incorporating new data or corrected diagnoses still requires careful validation to prevent poisoning.

