Summary
AI deployments commonly consist of four components: model, data, application, and system. We have explored security vulnerabilities in the model and data components in previous modules in the AI Red Teamer path. In this module, we will explore security vulnerabilities in the application and system components and discuss how they can affect the overall security of an AI deployment. Additionally, we will focus on the Model Context Protocol (MCP), its purpose, how it works, and how potential security issues may arise.
In more detail, this module covers the following:
- Security vulnerabilities in the
application component - Security vulnerabilities in the
system component - Overview of MCP
- Security vulnerabilities in MCP servers
- Security issues resulting from malicious MCP servers
This module is broken into sections with accompanying hands-on exercises to practice each of the tactics and techniques we cover. The module ends with a practical hands-on skills assessment to gauge your understanding of the various topic areas.
You can start and stop the module at any time and pick up where you left off. There is no time limit or "grading", but you must complete all of the exercises and the skills assessment to receive the maximum number of cubes and have this module marked as complete in any paths you have chosen.
A firm grasp of the following modules can be considered a prerequisite for the successful completion of this module:
Overview of Application & System Components
As we have discussed in detail in the Introduction to Red Teaming AI module, real-world AI deployments typically consist of four distinct components:

Previous modules in the AI Red Teamer path focused on attack vectors on the model, such as the Prompt Injection Attacks and LLM Output Attacks modules, or the data, such as the AI Data Attacks module.
This module will explore security vulnerabilities in the application and system components. Let us briefly recap what these two components entail. Furthermore, we will explore the Model Context Protocol (MCP), an orchestration protocol for AI applications introduced by the AI company Anthropic in 2024.
Application Component
The application component serves as the interface layer, connecting users to the underlying model and its capabilities. It comprises all applications that the AI deployment interacts with, including web applications, mobile apps, APIs, databases, and integrated services such as plugins and autonomous agents. Since security vulnerabilities in systems interacting with the AI ecosystem often directly impact the security of the AI deployment, it is crucial to assess the application's overall security. In the real world, generative AI is being integrated into increasingly complex systems, providing a wide range of services. Due to the complexity of these deployments, security vulnerabilities may arise in interconnected systems or interfaces between the different integrations, potentially posing a risk for user data and model interactions.
Common application-component attacks include:
Injection attacks, such as SQL injection or command injection. Injection vulnerabilities can lead to loss of data or complete system takeover.Access control vulnerabilities, potentially enabling unauthorized attackers to access sensitive data or functionality.Denial of ML-Service, potentially impairing the availability of the AI deployment.Rogue Actions: If a model hasexcessive agencyand can access functions or data it does not necessarily need to access, the model may trigger unintended actions impacting systems it interfaces with. Such rogue actions may result from malicious intent or inadvertently occur due to unexpected interactions with the model. For instance, if the model can issue arbitrary SQL queries in a connected database, a model response may result in data loss if all tables are dropped. Such a query can either be issued maliciously by an attacker or accidentally caused by unexpected user input.Model Reverse Engineering: An attacker may be able to replicate the model by analyzing inputs and outputs for a vast number of input data points. If the application does not implement a rate limit, malicious actors may frequently query the model to reverse-engineer it.Vulnerable Agents or Plugins: Vulnerabilities in custom agents or plugins integrated into the deployment may perform unintended actions or exfiltrate model interactions to malicious actors.Logging of sensitive data: If the application logs sensitive data from user input or model interactions, sensitive information may be disclosed to unauthorized actors through application logs.
System Component
The system component encompasses all infrastructure-related elements, including deployment platforms, code, data storage, and hardware. For instance, it comprises the source code for training and running the model, including frameworks, storage for training and inference data, storage for the model itself, and the deployment pipeline to deploy the model in production. Security vulnerabilities at this layer can cascade across the entire deployment, as breaches may lead to total system compromise, unauthorized access to models and data, or service disruption.
Common system-component vulnerabilities include:
Misconfigured Infrastructure: If infrastructure used during training or inference is misconfigured to expose data or services to the public inadvertently, unauthorized actors may be able to steal training data, user data, the model itself, or configuration secrets.Improper Patch Management: Issues in an AI deployment application's patch management process may result in unpatched public vulnerabilities in different system components, from the operating system to the ML stack. These vulnerabilities can range from privilege escalation vectors to remote code execution flaws and may result in total system compromise.Network Security: Since generative AI deployments typically interface with different systems over internal networks, proper network security is crucial to mitigate security threats. Common network security measures include network segmentation, encryption, and monitoring to thwart lateral movement.Model Deployment Tampering: If threat actors manipulate the deployment process, they may be able to maliciously modify model behavior. They can achieve this by manipulating the source code or exploiting vulnerabilities.Excessive Data Handling: Applications processing and storing data excessively may run into legal issues if this data includes user-related information. Furthermore, excessive data handling increases the impact of data storage vulnerabilities as more data is at risk of being leaked or stolen.
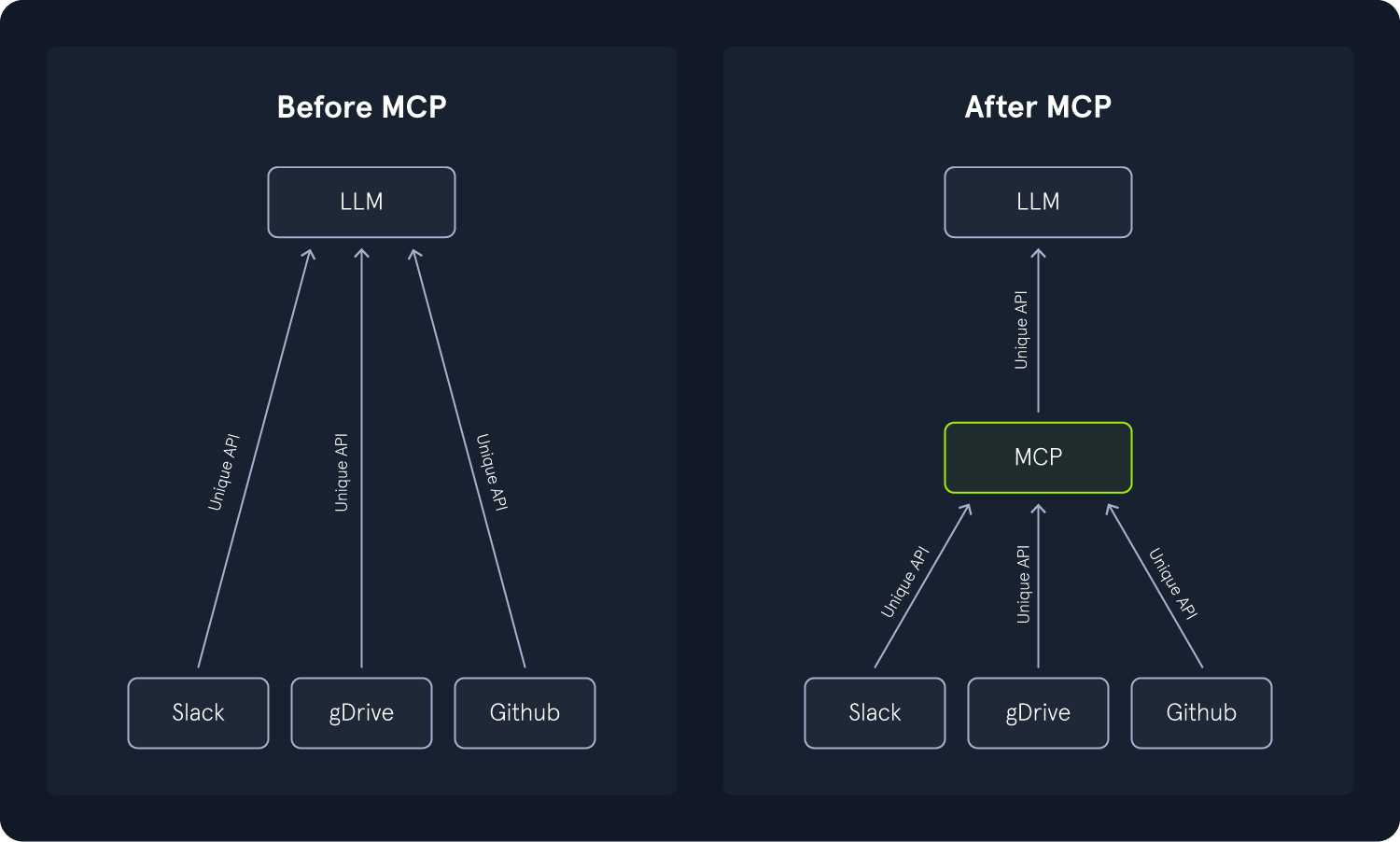
Model Context Protocol (MCP)
The Model Context Protocol (MCP) provides a standardized interface between LLM applications and external resources. As LLMs become increasingly capable, ensuring that these models can consistently interpret, retain, and apply context is crucial for achieving a satisfactory performance. MCP addresses this need by defining a structured framework for sharing, updating, and reasoning over context information between models and their environments, such as user interfaces, external APIs, or other data providers. At its core, MCP establishes a standardized method for representing context- and task-specific data.